IA
Novo Chip Qualcomm AI200 e Parceria com AWS : Tokens 90% mais Baratos
A Qualcomm AI200 promete derrubar custos de inferência em 90%. Mas nenhum chip funciona bem em uma rede instável. Veja por que conectividade B2B é agora o real diferencial competitivo em IA.
A Qualcomm está entrando no mercado de chips AI de data center com o AI200 e a AWS estuda adotá-lo para reduzir custos de inferência. Mas a queda de preços de tokens só funciona se sua infraestrutura de rede estiver à altura.

O AI200 da Qualcomm: Um Novo Jogador no Mercado de Inferência
Em outubro de 2025, a Qualcomm anunciou oficialmente seus novos chips de IA para data center: o AI200 (previsto para 2026) e o AI250 (2027). Esses processadores foram desenvolvidos com foco em um segmento específico que as grandes nuvens estão enfatizando: a inferência — a execução de modelos já treinados, não o treinamento deles.
Enquanto NVIDIA domina 80% do mercado com suas GPUs H100 e H200, a Qualcomm traz uma abordagem diferente. O AI200 oferece até 768 GB de memória LPDDR por cartão PCIe e pode ser configurado em um rack líquido completo que oferece impressionantes 43 TB de memória compartilhada. A proposta é clara: executar modelos de linguagem grandes (LLMs) de forma mais eficiente e barata que as soluções tradicionais.
O posicionamento do AI200 é baseado em custo total de propriedade (TCO) reduzido — não apenas pela placa em si, mas pelo consumo de energia e pela capacidade de processamento de muitas requisições simultâneas. A Humain, uma empresa de IA saudita, já se comprometeu a implantar 200 megawatts de capacidade AI200 em seus data centers a partir de 2026.
A AWS Estuda Adotar o AI200: Um Sinal de Mudança no Mercado
Segundo análise de dados do Wells Fargo, a Amazon Web Services (AWS) é apontada como potencial parceira estratégica para a Qualcomm no uso do AI200. Embora não haja um anúncio oficial de parceria confirmada, a sinalização é forte: a AWS está sob pressão para melhorar as margens operacionais de seus serviços de IA.
Por quê? Porque a inferência em larga escala é cara. Bilhões de requisições diárias de usuários testando ChatGPT, Claude, Gemini e outros LLMs custam centenas de milhões de dólares por mês em infraestrutura. Uma redução de 30%, 40% ou mais nesses custos — como o AI200 promete — seria um ganho competitivo enorme para a AWS.
É importante notar: essa parceria ainda é especulativa, baseada em análises de analistas. Mas o fato de a AWS estar considerando alternativas a NVIDIA como fornecedor de chips é um indicativo de que o mercado está mudando. A AWS também faz uso de chips Trainium e Inferentia (seus próprios ASICs personalizados) e recentemente implantou os sistemas Cerebras CS-3 que entregam até 5x mais throughput de tokens com o mesmo custo que GPUs tradicionais.

O Impacto Real: Tokens Mais Baratos (Muito Mais Baratos)
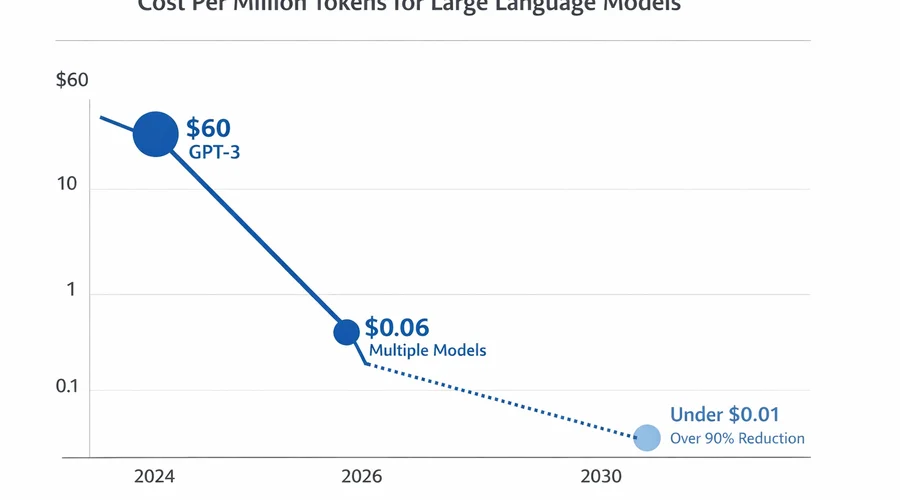
Os números falam por si. Em 2024, o GPT-3 original custava $60 por milhão de tokens. Em 2026, múltiplos modelos já excedem o desempenho do GPT-3 por $0,06 por milhão de tokens — uma queda de 1000 vezes em dois anos.
Segundo Gartner, até 2030, executar inferência em um modelo de um trilhão de parâmetros custará mais de 90% menos do que em 2025, devido a:
- Melhorias em semicondutores especializados (como o AI200)
- Inovações de design de modelos (destilação, quantização, pruning)
- Maior utilização de chips
- Aumento do uso de computação de borda em dispositivos locais
Para um CTO ou responsável de TI de uma empresa, isso significa: IA está ficando tão barata que cabe no orçamento. Um modelo de IA rodando 24/7 que custo $10.000 por mês em 2025 pode custar $1.000 por mês em 2027.
Mas há um “mas”.
O Segredo que Ninguém Fala: A Rede É Agora o Gargalo
Há uma realidade que as empresas de semicondutores não mencionam em seus comunicados à imprensa: nenhum chip, por mais eficiente que seja, funciona bem em uma rede instável.
A IA de inferência em escala empresarial é fundamentalmente diferente do treinamento. Enquanto treinar um modelo é uma operação em lote (você carrega tudo, deixa rodando por horas e colhe o resultado), a inferência é latência-sensível e contínua. Um usuário envia uma pergunta para um chatbot, a requisição viaja até o data center da cloud, o modelo processa, e a resposta volta — tudo isso precisa acontecer em menos de 500ms para parecer “responsivo”.
Quando empresas começam a usar IA em larga escala — para atender clientes, automatizar processos internos, alimentar análises em tempo real — essas requisições se multiplicam. Centenas, milhares por minuto. E cada uma depende de:
- Latência baixa e consistente (não basta “rápido”, precisa ser previsível)
- Jitter mínimo (variações de latência matam a experiência do usuário)
- Banda garantida (picos de tráfego não podem congestionar a rede)
- Disponibilidade alta (uma queda de rede desativa toda a IA da empresa)
Isso é especialmente crítico em cenários B2B. Quando você oferece IA como parte de seu serviço a clientes — uma consultoria que usa IA para análise, uma fintech que usa IA para detecção de fraude, um e-commerce que usa IA para recomendações — a qualidade de sua rede é a qualidade de sua IA aos olhos do cliente.
A Cisco e o Ericsson mapearam isso em 2026: as redes empresariais estão sofrendo uma transformação radical. O tráfego deixou de ser “paced by humans” (movido por humanos) para ser “paced by machines” (movido por máquinas). Máquinas geram 100 vezes mais requisições que humanos, com zero pausas nos off-hours. Uma rede que era “boa o suficiente” para comunicação executiva cai quando você joga 1 milhão de requisições de IA por segundo nela.
Conectividade B2B: O Diferencial Competitivo que Ninguém Vê
Enquanto o mercado toda célèbre a queda de preços de tokens e a chegada de novos chips, as empresas que realmente vão ganhar com IA nos próximos 18 meses são aquelas que resolvem o problema de rede primeiro.
Pense em um caso concreto: uma distribuidora de energia que quer usar IA para:
- Prever demanda energética de forma mais precisa
- Automatizar análise de defeitos em linhas de transmissão (usando visão computacional)
- Oferecer ao cliente uma interface de chat para dúvidas sobre consumo
Tudo isso custa 90% menos em 2026 do que teria custado em 2024. Mas se a rede interna da empresa for instável — se houver latência, congestionamento, ou falhas de conectividade entre os postos de atendimento, as subestações e o data center central — a IA fica inútil. O chatbot demora 5 segundos para responder (inaceitável). As predições chegam tarde (perdem valor). A visão computacional falha às vezes porque a câmera perde conexão.
Agora multiplique isso por centenas de empresas descobrindo isso simultaneamente em 2026-2027. Uma rede B2B moderna não é um “nice to have” — é o alicerce de qualquer estratégia de IA.
Estabilidade de Rede = Competitividade em IA
A queda de custos de tokens está criando uma oportunidade histórica: IA está ficando acessível. Mas essa acessibilidade só vale se você conseguir usar a IA de forma confiável.
Empresas que investem em conectividade B2B estável agora — antes do pico de adoção de IA — terão uma vantagem de 12-18 meses sobre concorrentes. Elas conseguirão:
- Deploy mais rápido de casos de uso de IA (sem delays de rede)
- Melhor experiência do cliente (latência baixa em interfaces alimentadas por IA)
- Economia de escala (cada watt gasto em IA rende mais valor)
- Redução de risco (rede confiável = IA confiável)
Por outro lado, empresas que deixam a rede para depois descobrirão um problema: quando chegarem ao mercado com suas soluções de IA, estarão começando a resolver problemas de infraestrutura que competitors já resolveram. Serão sempre mais lentos, mais caros, menos confiáveis.
O Timing É Agora
A Qualcomm está entrando no mercado. A AWS está estudando como integrar novos chips. Os preços de tokens estão caindo exponencialmente. Essas três tendências criam um ponto de inflexão: 2026-2027 é o ano em que empresas realmente começam a usar IA em produção, não em POC.
Mas o sucesso não vai para quem tem o chip mais barato. Vai para quem consegue usar esse chip de forma confiável, com latência previsível, para servir clientes. E isso só é possível com uma rede à altura.
Se sua empresa está planejando investir em IA este ano, converse com seu time de TI sobre um diagnóstico de rede. Não é uma questão de “ter internet”. É uma questão de ter a rede certa para que sua IA funcione.
Conteúdo B2B sobre conectividade, infraestrutura digital e gestão de TI — direto na caixa de entrada, sem spam.
Sua operação merece uma rede à altura. Engenharia local em Manaus, SLA contratual e suporte humano 24/7. Avaliamos a viabilidade técnica no seu endereço antes de qualquer proposta. Nossa equipe entra em contato em até 1 dia útil com uma proposta sob medida.Fale com um especialista da Upnetix